常见函数用法
常见函数用法
1.read
1 | read(0, buf, 0xAuLL); |
用法:
1 | ssize_t read(int fd, void *buf, size_t count); |
参数解释:
fd:文件描述符,表示要读取的文件或者输入源。在 UNIX 系统中,0 表示标准输入(STDIN),1 表示标准输出(STDOUT),2 表示标准错误(STDERR)。
- 文件描述符0:用于接收用户输入或者从管道、重定向或者其他输入源读取数据。
- 文件描述符1:用于向终端或者其他输出目标输出数据。
buf:指向存储读取数据的缓冲区的指针。
count:要读取的最大字节数。
注:0xAuLL 中的 uLL 表示这是一个无符号长长整型(unsigned long long)的常量,sleep(0x1BF52u)中的u表示无符号整型(unsigned)。
2.strcat
1 | strcat(dest, buf); |
这行代码将用户输入的内容追加到 dest 字符串后面
双击跟进 dest
可以看到 dest 被声明为一个大小为 4 字节的字符数组,用来存储字符串
详细解释:
dest 是一个标签(label),它是程序中一个位置的名称或者符号。
db 是汇编语言中的伪指令(pseudo-instruction),用于声明字节(byte)类型的数据。
4 表示数组的大小为4字节。
dup(?) 表示重复(duplicate)未知值(?)4次,即将4个未知值(通常为0)依次填充到数组中。

3.setvbuf
描述
C 库函数 int setvbuf(FILE *stream, char *buffer, int mode, size_t size) 定义流 stream 应如何缓冲。
stream: 指向需要设置缓冲区的流(stdin,stdout)
buf: 指向缓冲区的指针。
mode: 表示缓冲方式,值为0表示全缓冲(只有缓冲区填满才会输出);值为1表示行缓冲(当遇到换行符或缓冲区满时输出);值为2表示无缓冲(数据直接输出)。
size: 表示缓冲区大小。
返回值: 如果返回0表示函数调用成功,缓冲区设置成功。反之,函数调用失败。
声明
下面是 setvbuf() 函数的声明。
1 | int setvbuf(FILE *stream, char *buffer, int mode, size_t size) |
参数
- stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了一个打开的流。
- buffer – 这是分配给用户的缓冲。如果设置为 NULL,该函数会自动分配一个指定大小的缓冲。
- mode – 这指定了文件缓冲的模式:
| 模式 | 描述 |
|---|---|
| _IOFBF | 全缓冲:对于输出,数据在缓冲填满时被一次性写入。对于输入,缓冲会在请求输入且缓冲为空时被填充。 |
| _IOLBF | 行缓冲:对于输出,数据在遇到换行符或者在缓冲填满时被写入,具体视情况而定。对于输入,缓冲会在请求输入且缓冲为空时被填充,直到遇到下一个换行符。 |
| _IONBF | 无缓冲:不使用缓冲。每个 I/O 操作都被即时写入。buffer 和 size 参数被忽略。 |
- size –这是缓冲的大小,以字节为单位。
无缓冲模式(第二个参数为 0,第三个参数为 2 表示_IONBF 模式)
返回值
如果成功,则该函数返回 0,否则返回非零值。
实例
下面的实例演示了 setvbuf() 函数的用法。
1 |
|
让我们编译并运行上面的程序,这将产生以下结果。在这里,程序把缓冲输出保存到 buff,直到首次调用 fflush() 为止,然后开始缓冲输出,最后休眠 5 秒钟。它会在程序结束之前,发送剩余的输出到 STDOUT。
1 | 启用全缓冲 |
例题
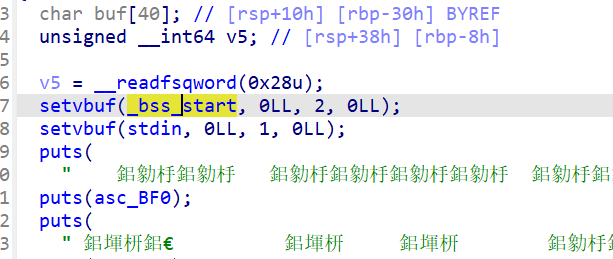
v5 = __readfsqword(0x28u);
从线程本地存储 (FS segment) 的 0x28 偏移读取栈 canary(栈保护机制);
如果栈被溢出破坏,函数返回前会检查这个值是否被改动,如果改变就会触发异常/崩溃。
setvbuf(_bss_start, 0LL, 2, 0LL);
✅ 重点:这句很不常见!
通常:setvbuf(stdout, NULL, _IONBF, 0) 用来设置 stdout 的缓冲模式。
但这里设置的是 _bss_start,这是**.bss 段的起始地址**,不应该是 FILE 指针!
说明:这行是为了造成混淆或隐藏 stdout 的关闭行为,你会发现这实际上等价于关闭了 stdout,或至少破坏了它的使用。
类似行为在前文提到的:
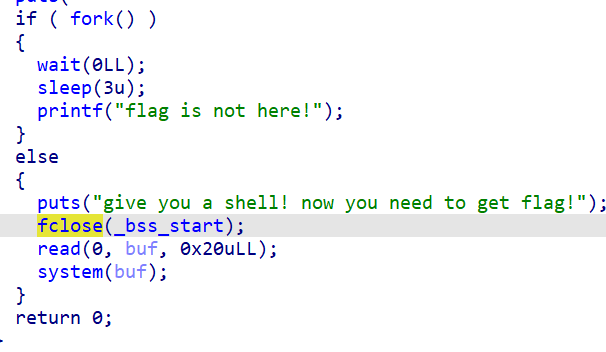
fclose(_bss_start);
也是一样的意图。
所以:
这句话的目的其实是 使程序不能正常通过 printf/puts 输出结果,增加难度。
setvbuf(stdin, 0LL, 1, 0LL);
关闭 stdin 的缓冲,使得输入行为是行缓冲或无缓冲;
这让输入变得更实时,对交互有帮助。
构造方法:
cat /ctf* 1>&0
1>&0是什么意思?
这是 Bash 的 文件描述符重定向语法,意思是:把 标准输出(1) 重定向到 标准输入(0)
也就是说:
cat原本写入 stdout- 现在
stdout被重定向到了stdin,而你还可以通过stdin接收数据(比如和程序交互时)
为什么这样能显示出 flag?
- 虽然
stdout被程序关闭或破坏了,但stdin(描述符 0)还在;- 通过
1>&0,让cat输出重定向到你还能“看见”的地方;- 因为你是通过
read+system(buf)执行命令,这个子进程的输出其实是能从 stdin 中读到的;- 很多 CTF 沙箱中使用 pseudo terminal / 父进程通信 / pipe 来连接 stdin/stdout,所以这样能“绕过关闭 stdout”的限制。
4.fork
例题
fork开启了一个全新的进程,返回两次返回值,父进程返回子进程的PID,子进程返回值为0(如果出现错误,fork返回一个负值),题目中当fork被调用,先是父进程返回值,因此PID>0,执行if下面的代码,wait(0LL)执行,父进程堵塞,等待子进程结束,父进程将被挂起,直到子进程完成,sleep(3u)是等待3s。此时的子进程中,fork返回0,进入else,关闭了输出流,然后从标准输入中读取了32个字节到buf,然后执行system(&buf)。
引用一位网友的话来解释fpid的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id, 因为子进程没有子进程,所以其fpid为0.
总结
很多 CTF 沙箱中使用 pseudo terminal / 父进程通信 / pipe 来连接 stdin/stdout,所以这样能“绕过关闭 stdout”的限制。
5.waitpid()
大家知道,当用fork启动一个新的子进程的时候,子进程就有了新的生命周期,并将在其自己的地址空间内独立运行。但有的时候,我们希望知道某一个自己创建的子进程何时结束,从而方便父进程做一些处理动作。同样的,在用ptrace去attach一个进程滞后,那个被attach的进程某种意义上说可以算作那个attach它进程的子进程,这种情况下,有时候就想知道被调试的进程何时停止运行。
以上两种情况下,都可以使用Linux中的waitpid()函数做到。先来看看waitpid函数的定义:
定义:
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid,int *status,int options);
cpp
运行
如果在调用waitpid()函数时,当指定等待的子进程已经停止运行或结束了,则waitpid()会立即返回;但是如果子进程还没有停止运行或结束,则调用waitpid()函数的父进程则会被阻塞,暂停运行。
参数:
下面来解释以下调用参数的含义:
1)pid_t pid
参数pid为欲等待的子进程识别码,其具体含义如下:
参数值 说明
pid<-1 等待进程组号为pid绝对值的任何子进程。
pid=-1 等待任何子进程,此时的waitpid()函数就退化成了普通的wait()函数。
pid=0 等待进程组号与目前进程相同的任何子进程,也就是说任何和调用waitpid()函数的进程在同一个进程组的进程。
pid>0 等待进程号为pid的子进程。
2)int *status
这个参数将保存子进程的状态信息,有了这个信息父进程就可以了解子进程为什么会推出,是正常推出还是出了什么错误。如果status不是空指针,则状态信息将被写入
器指向的位置。当然,如果不关心子进程为什么推出的话,也可以传入空指针。
Linux提供了一些非常有用的宏来帮助解析这个状态信息,这些宏都定义在sys/wait.h头文件中。主要有以下几个:
宏 说明
WIFEXITED(status) 如果子进程正常结束,它就返回真;否则返回假。
WEXITSTATUS(status) 如果WIFEXITED(status)为真,则可以用该宏取得子进程exit()返回的结束代码。
WIFSIGNALED(status) 如果子进程因为一个未捕获的信号而终止,它就返回真;否则返回假。
WTERMSIG(status) 如果WIFSIGNALED(status)为真,则可以用该宏获得导致子进程终止的信号代码。
WIFSTOPPED(status) 如果当前子进程被暂停了,则返回真;否则返回假。
WSTOPSIG(status) 如果WIFSTOPPED(status)为真,则可以使用该宏获得导致子进程暂停的信号代码。
3)int options
参数options提供了一些另外的选项来控制waitpid()函数的行为。如果不想使用这些选项,则可以把这个参数设为0。
主要使用的有以下两个选项:
参数 说明
WNOHANG 如果pid指定的子进程没有结束,则waitpid()函数立即返回0,而不是阻塞在这个函数上等待;如果结束了,则返回该子进程的进程号。
WUNTRACED 如果子进程进入暂停状态,则马上返回。
这些参数可以用“|”运算符连接起来使用。
如果waitpid()函数执行成功,则返回子进程的进程号;如果有错误发生,则返回-1,并且将失败的原因存放在errno变量中。
失败的原因主要有:没有子进程(errno设置为ECHILD),调用被某个信号中断(errno设置为EINTR)或选项参数无效(errno设置为EINVAL)
如果像这样调用waitpid函数:waitpid(-1, status, 0),这此时waitpid()函数就完全退化成了wait()函数。
 wechat
wechat alipay
alipay


